NeurIPS 2018
Stochastic regularisation is an important weapon in the arsenal of a deep learning practitioner.
However, despite recent theoretical advances, our understanding of how noise influences signal propagation in deep neural networks remains limited.
By extending recent work based on mean field theory, we develop a new framework for signal propagation in stochastic regularised neural networks.
Our noisy signal propagation theory can incorporate several common noise distributions, including additive and multiplicative Gaussian noise as well as dropout.
We use this framework to investigate initialisation strategies for noisy ReLU networks.
We show that no critical initialisation strategy exists using additive noise, with signal propagation exploding regardless of the selected noise distribution.
For multiplicative noise (eg. dropout), we identify alternative critical initialisation strategies that depend on the second moment of the noise distribution.
Simulations and experiments on real-world data confirm that our proposed initialisation is able to stably propagate signals in deep networks, while using an initialisation disregarding noise fails to do so.
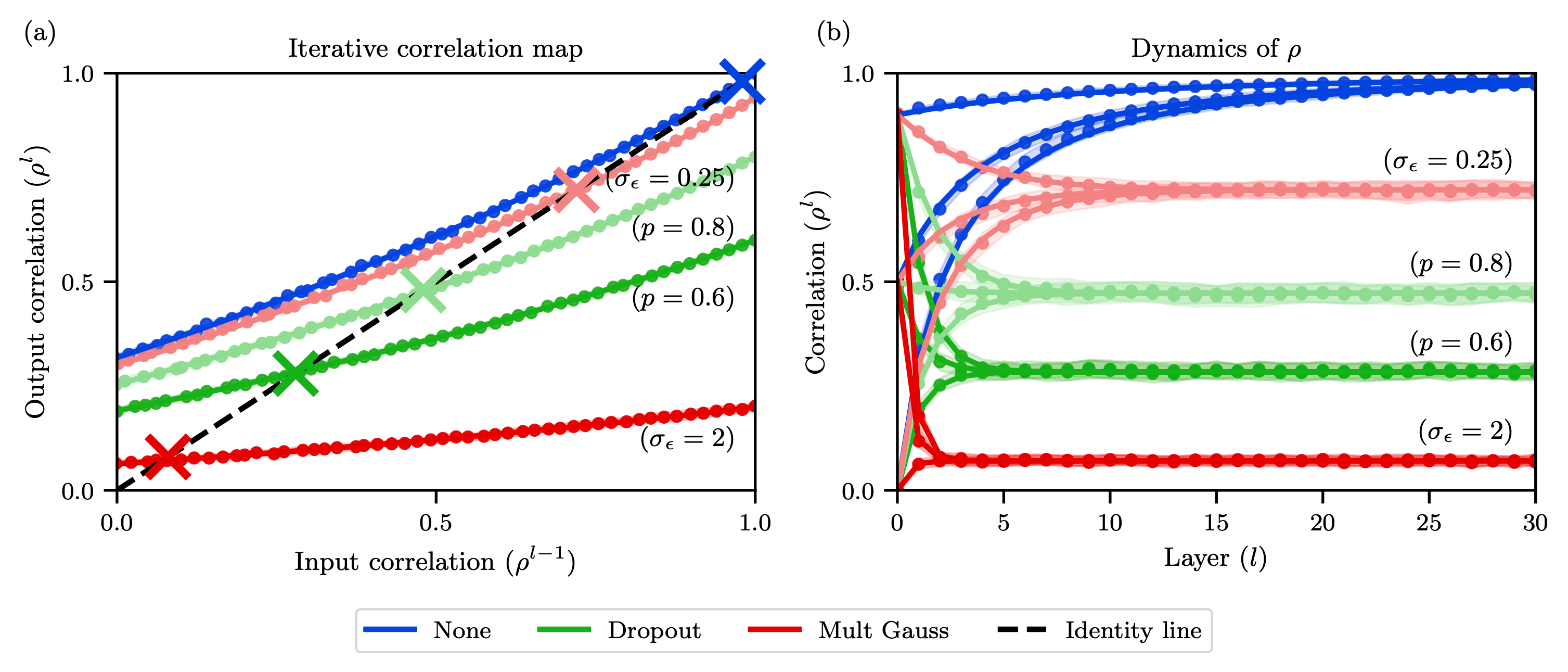
Furthermore, we analyse correlation dynamics between inputs.
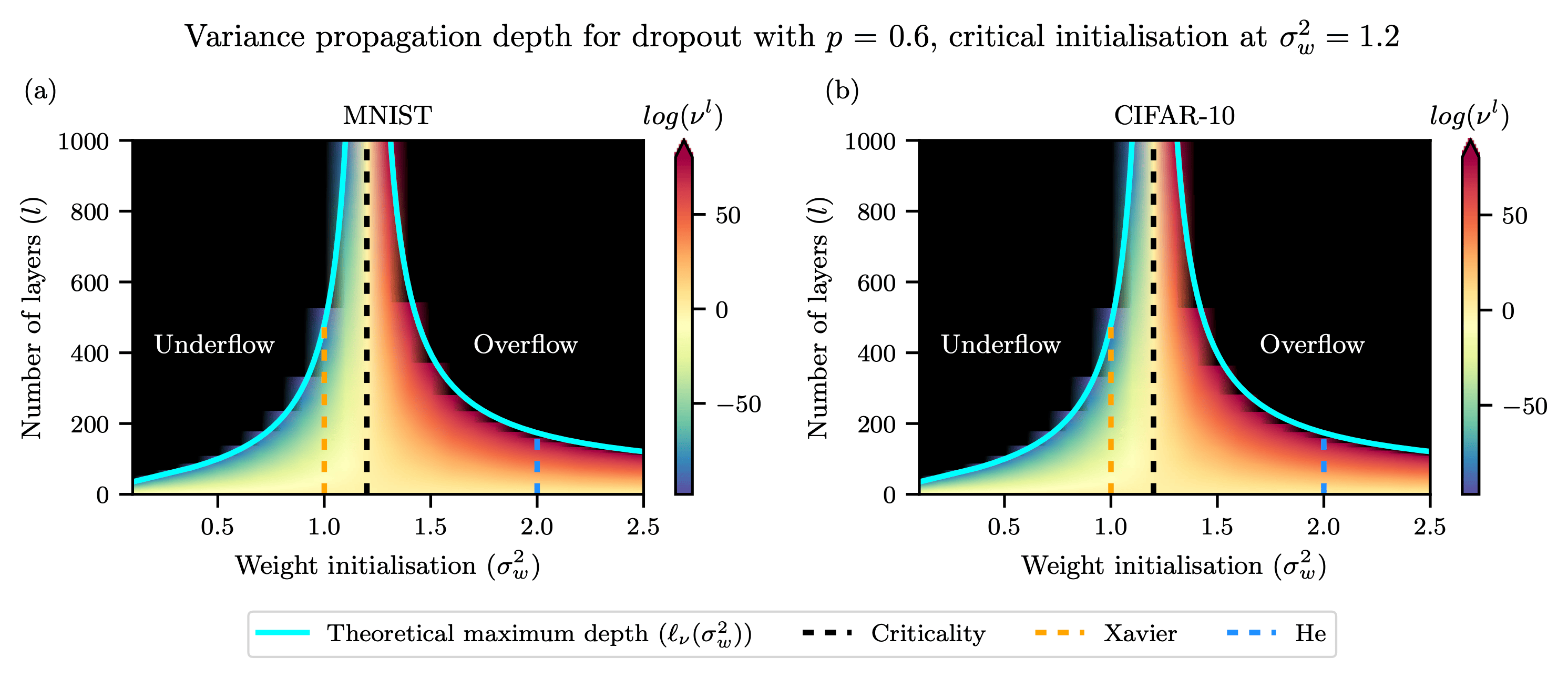
Stronger noise regularisation is shown to reduce the depth to which discriminatory information about the inputs to a noisy ReLU network is able to propagate, even when initialised at criticality.
We support our theoretical predictions for these trainable depths with simulations, as well as with experiments on MNIST and CIFAR-10.
Pattern Recognition Letters 2020
Recent work in signal propagation theory has shown that dropout limits the depth to which information can propagate through a neural network.
In this paper, we investigate the effect of initialisation on training speed and generalisation for ReLU networks within this depth limit.
We ask the following research question: given that critical initialisation is crucial for training at large depth, if dropout limits the depth at which networks are trainable, does initialising critically still matter?
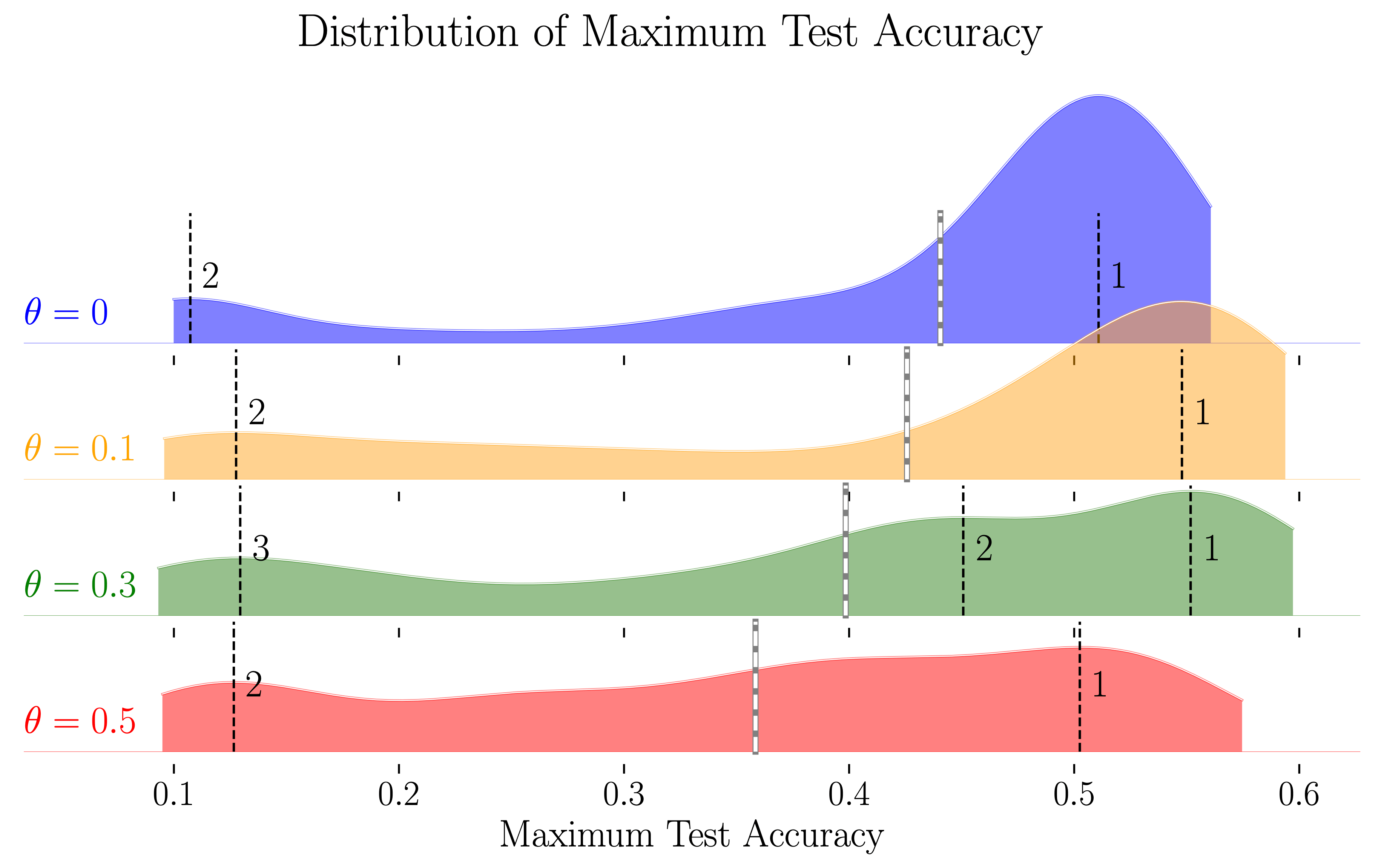
We conduct a large-scale controlled experiment, and perform a statistical analysis of over 12000 trained networks.
We find that (1) trainable networks show no statistically significant difference in performance over a wide range of non-critical initialisations;
(2) for initialisations that show a statistically significant difference, the net effect on performance is small;
(3) only extreme initialisations (very small or very large) perform worse than criticality.
These findings also apply to standard ReLU networks of moderate depth as a special case of zero dropout.
Our results therefore suggest that, in the shallow-to-moderate depth setting, critical initialisation provides zero performance gains when compared to off-critical initialisations and that searching for off-critical initialisations that might improve training speed or generalisation, is likely to be a fruitless endeavour.
Stellenbosch University 2021
Recently, proper initialisation and stochastic regularisation techniques have greatly improved the performance and ease of training of neural networks.
Some research has gone into how the magnitude of the initial weights impact optimisation, while others have focused on how initialisation affects signal propagation.
In terms of noise regularisation, dropout has allowed networks to train relatively quickly and reduced overfitting.
Much research has gone towards understanding why dropout improves the generalisation of networks.
Two major theories are (i) that it prevents neurons from becoming too dependent on the output of other neurons and (ii) that dropout leads a network to optimise a smoother loss landscape.
Despite this, our theoretical understanding of the interaction between regularisation and initialisation is sparse.
Thus, the aim of this work was to broaden our knowledge of how initialisation and stochastic regularisation interact and what impact this has on network training and performance.
Because rectifier activation functions are widely used, we extended new network signal propagation theory to rectifier networks that may use stochastic regularisation.
Our theory predicted a critical initialisation that allows for stable pre-activation variance signal propagation.
However, our theory also indicated that stochastic regularisation reduces the depth to which correlation information can propagate in ReLU networks.
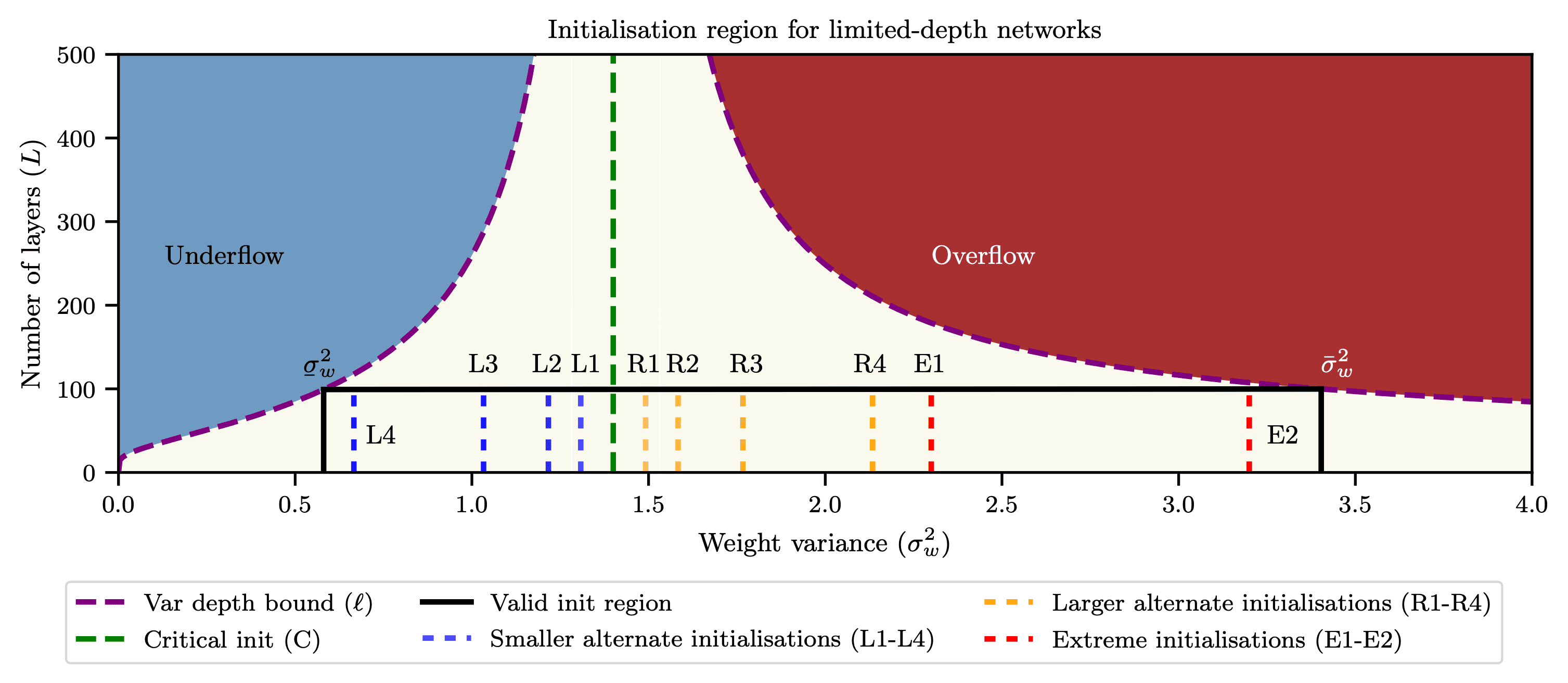
We validated this theory and showed that it accurately predicts a boundary across which networks do not train effectively.
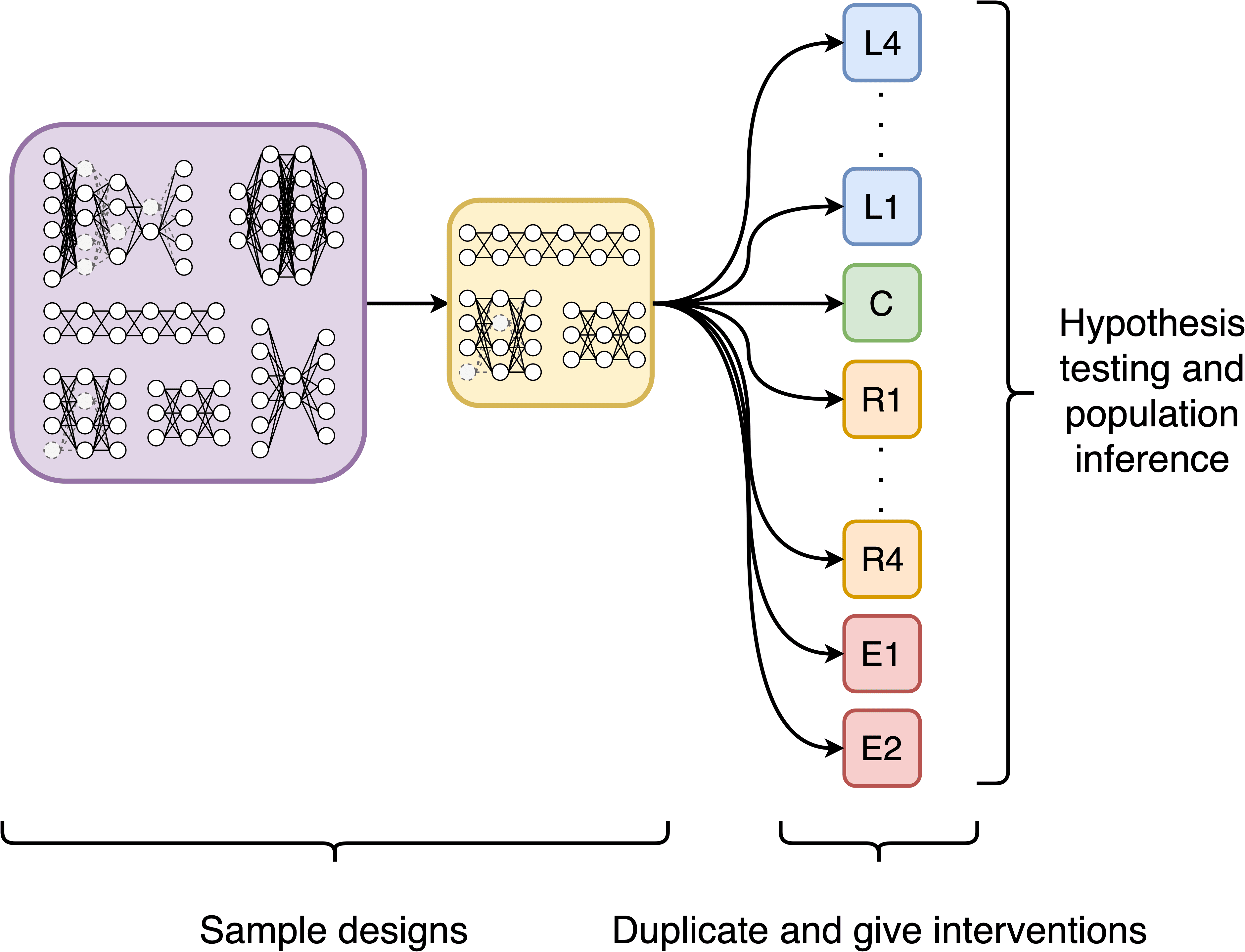
We then extended the investigation by conducting a large-scale randomised control trial to search for initialisations in a region that conserves input signal around the critical initialisation in the hopes of finding initialisations that provide advantages to training or generalisation.
We compare the critical initialisation to 10 other initialisation schemes in a trial that consisted of over 12000 networks.
We found that initialisations much larger than the critical initialisation provide extremely poor performance, while network initialisations close to the critical initialisation provide similar performance.
No initialisations clearly outperformed the critical initialisation.
Thus, we recommend it as a safe default for practitioners.
NeurIPS 2020
Multi-agent reinforcement learning has recently shown great promise as an approach to networked system control.
Arguably, one of the most difficult and important tasks for which large scale networked system control is applicable is common-pool resource management.
Crucial common-pool resources include arable land, fresh water, wetlands, wildlife, fish stock, forests and the atmosphere, of which proper management is related to some of society's greatest challenges such as food security, inequality and climate change.
Here we take inspiration from a recent research program investigating the game-theoretic incentives of humans in social dilemma situations such as the well-known tragedy of the commons.
However, instead of focusing on biologically evolved human-like agents, our concern is rather to better understand the learning and operating behaviour of engineered networked systems comprising general-purpose reinforcement learning agents, subject only to non-biological constraints such as memory, computation and communication bandwidth.
Harnessing tools from empirical game-theoretic analysis, we analyse the differences in resulting solution concepts that stem from employing different information structures in the design of networked multi-agent systems.
These information structures pertain to the type of information shared between agents as well as the employed communication protocol and network topology.
Our analysis contributes new insights into the consequences associated with certain design choices and provides an additional dimension of comparison between systems beyond efficiency, robustness, scalability and mean control performance.
OpenReview.net 2021
The human imagination is an integral component of our intelligence.
Furthermore, the core utility of our imagination is deeply coupled with communication.
Language, argued to have been developed through complex interaction within growing collective societies serves as an instruction to the imagination, giving us the ability to share abstract mental representations and perform joint spatiotemporal planning.
In this paper, we explore communication through imagination with multi-agent reinforcement learning.
Specifically, we develop a model-based approach where agents jointly plan through recurrent communication of their respective predictions of the future.
Each agent has access to a learned world model capable of producing model rollouts of future states and predicted rewards, conditioned on the actions sampled from the agent's policy.
These rollouts are then encoded into messages and used to learn a communication protocol during training via differentiable message passing.
We highlight the benefits of our model-based approach, compared to a set of strong baselines, by developing a set of specialised experiments using novel as well as well-known multi-agent environments.
Stellenbosch University 2017
Reinforcement learning is a relatively new and undiscovered branch of machine learning.
However, reinforcement learning has recently become very popular.
Even so, very few understand what reinforcement learning is and possible applications thereof.
This project report serves to give an overview of reinforcement learning and will explain some of the recently developed approaches, such as deep Q learning.
Throughout this report, we build our understanding of reinforcement learning until we reach the level of deep Q learning.
We then apply a deep Q network to a computer game, Code vs Zombies.
While our implementation stabilised on a suboptimal policy when playing the full game, it was able to find optimal policies for constrained versions.
In the process, we experiment with and optimise some of the leading approaches in reinforcement learning.
arXiv 2019
For our submission to the ZeroSpeech 2019 challenge, we apply discrete latent-variable neural networks to unlabelled speech and use the discovered units for speech synthesis.
Unsupervised discrete subword modelling could be useful for studies of phonetic category learning in infants or in low-resource speech technology requiring symbolic input.
We use an autoencoder (AE) architecture with intermediate discretisation.
We decouple acoustic unit discovery from speaker modelling by conditioning the AE's decoder on the training speaker identity.
At test time, unit discovery is performed on speech from an unseen speaker, followed by unit decoding conditioned on a known target speaker to obtain reconstructed filterbanks.
This output is fed to a neural vocoder to synthesise speech in the target speaker's voice. For discretisation, categorical variational autoencoders (CatVAEs), vector-quantised VAEs (VQ-VAEs) and straight-through estimation are compared at different compression levels on two languages.
Our final model uses convolutional encoding, VQ-VAE discretisation, deconvolutional decoding and an FFTNet vocoder.
We show that decoupled speaker conditioning intrinsically improves discrete acoustic representations, yielding competitive synthesis quality compared to the challenge baseline.
arXiv 2020
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved.
"Low-resourced"-ness is a complex problem going beyond data availability and reflects systemic problems in society.
In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide.
Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages.
As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process.
We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages.
Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution.
Benchmarks, models, data, code, and evaluation results are released under https://github.com/masakhane-io/masakhane-mt.
arXiv 2020
Africa has over 2000 languages.
Despite this, African languages account for a small portion of available resources and publications in Natural Language Processing (NLP).
This is due to multiple factors, including: a lack of focus from government and funding, discoverability, a lack of community, sheer language complexity, difficulty in reproducing papers and no benchmarks to compare techniques.
To begin to address the identified problems, MASAKHANE, an open-source, continent-wide, distributed, online research effort for machine translation for African languages, was founded.
In this paper, we discuss our methodology for building the community and spurring research from the African continent, as well as outline the success of the community in terms of addressing the identified problems affecting African NLP.
arXiv 2020
Transformers have shown great promise as an approach to Neural Machine Translation (NMT) for low-resource languages.
However, at the same time, transformer models remain difficult to optimize and require careful tuning of hyper-parameters to be useful in this setting.
Many NMT toolkits come with a set of default hyper-parameters, which researchers and practitioners often adopt for the sake of convenience and avoiding tuning.
These configurations, however, have been optimized for large-scale machine translation data sets with several millions of parallel sentences for European languages like English and French.
In this work, we find that the current trend in the field to use very large models is detrimental for low-resource languages, since it makes training more difficult and hurts overall performance, confirming previous observations.
We see our work as complementary to the Masakhane project ("Masakhane" means "We Build Together" in isiZulu.)
In this spirit, low-resource NMT systems are now being built by the community who needs them the most.
However, many in the community still have very limited access to the type of computational resources required for building extremely large models promoted by industrial research.
Therefore, by showing that transformer models perform well (and often best) at low-to-moderate depth, we hope to convince fellow researchers to devote less computational resources, as well as time, to exploring overly large models during the development of these systems.